Cribl LogStream and TrackMe integration¶
If you are using Cribl LogStream, you can easily integrate TrackMe in a just a few steps, using the excellent native Cribl LogStream design, TrackMe will take into account the concept of pipelines to create, monitor and render the data sources automatically.
In a nutshell:
- A configuration parameter is available in TrackMe to enable the Cribl mode
- Once activated, the Cribl mode updates the way TrackMe is identifying and breaking the data sources
- To achieve this, TrackMe relies on the cribl_pipe indexed field automatically created by LogStream when data is indexed in Splunk
- Related searches transparenly use the cribl_pipe information, that accurately represents the data pipeline as it should be monitored, from LogStream to Splunk
Enable the Cribl mode¶
To enable the Cribl mode, go in “TrackMe manage and configure” and click on the enable Cribl mode:

Once the Cribl mode is enabled, perform a reset of the data source collection:

Cribl mode data sources¶
Let’s assume the following simple scenario:
- Cribl LogStream receives incoming data from any kind of sources, and streams to Splunk with associated pipelines
- In our example, we instruct LogStream to index data in Splunk into a few indexes, but we have many more pipelines since we perform various operations on LogStream, indexes and sourcetypes are likely fed by much more than just one pipeline
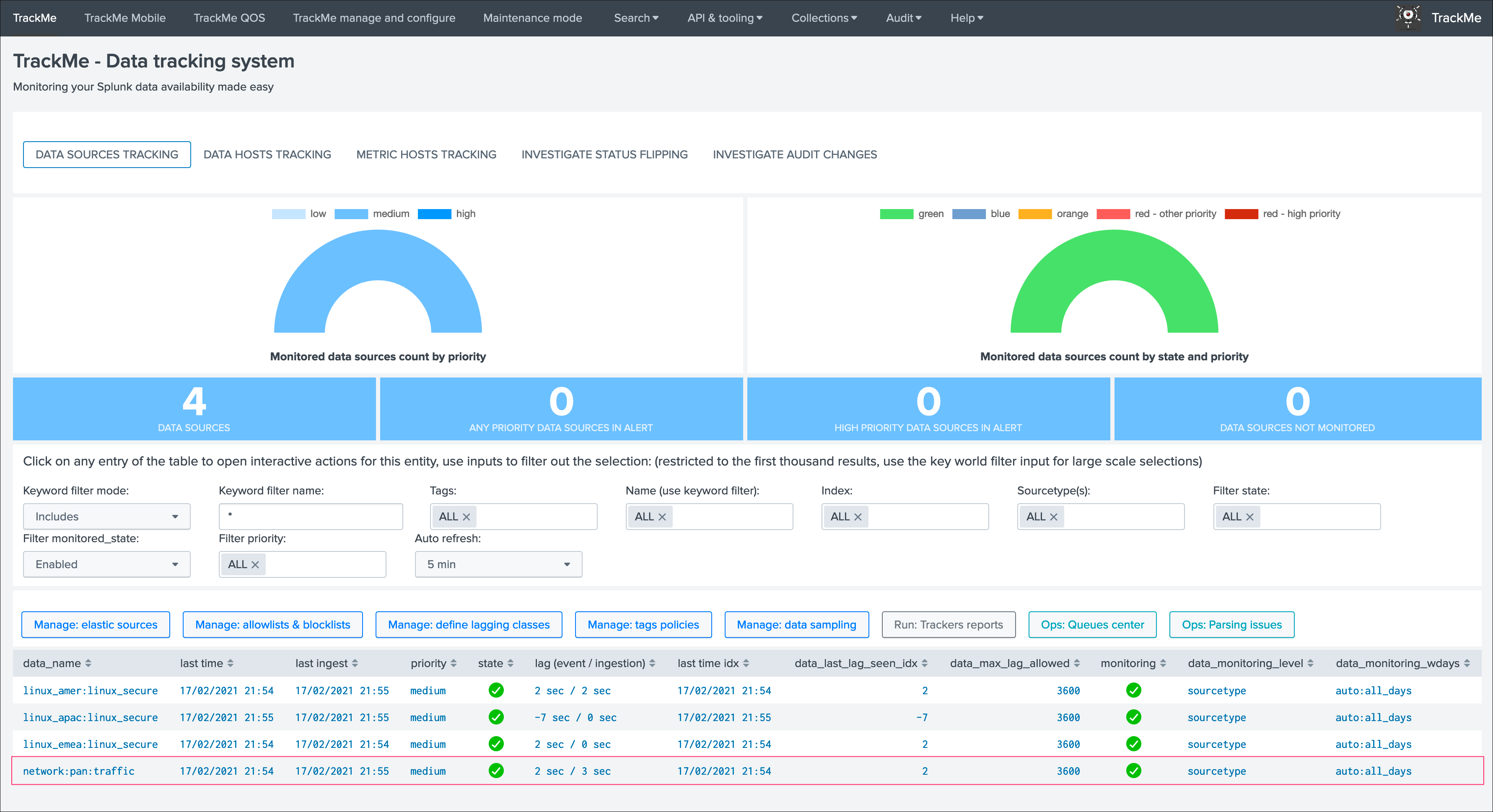
- In regular TrackMe mode, TrackMe would represent the data sources broken by indexes and sourcetypes, however, this does not represent what the incoming data flow is underneath, and does not provide the valuable information and monitoring layer we need
- Once we enable the Cribl mode, TrackMe relies on the
cribl_pipepipeline information to properly distinguish the real data flow as it is from the data provider (Cribl LogStream) perspective
Cribl LogStream pipeline examples:
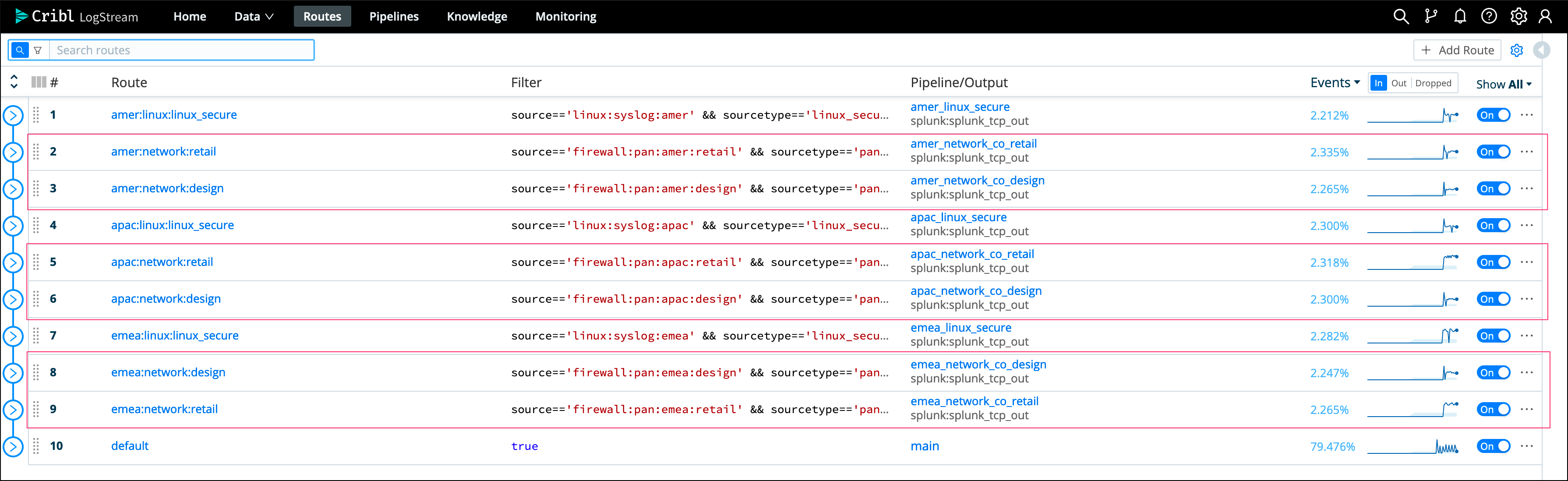
In this example, the default TrackMe mode has different issues, we stream data to an index called “network”, however we have different pipelines that are potentially linked to multiple sources and from the LogStream point of view could be affected independently in case of an issue or misconfiguration:
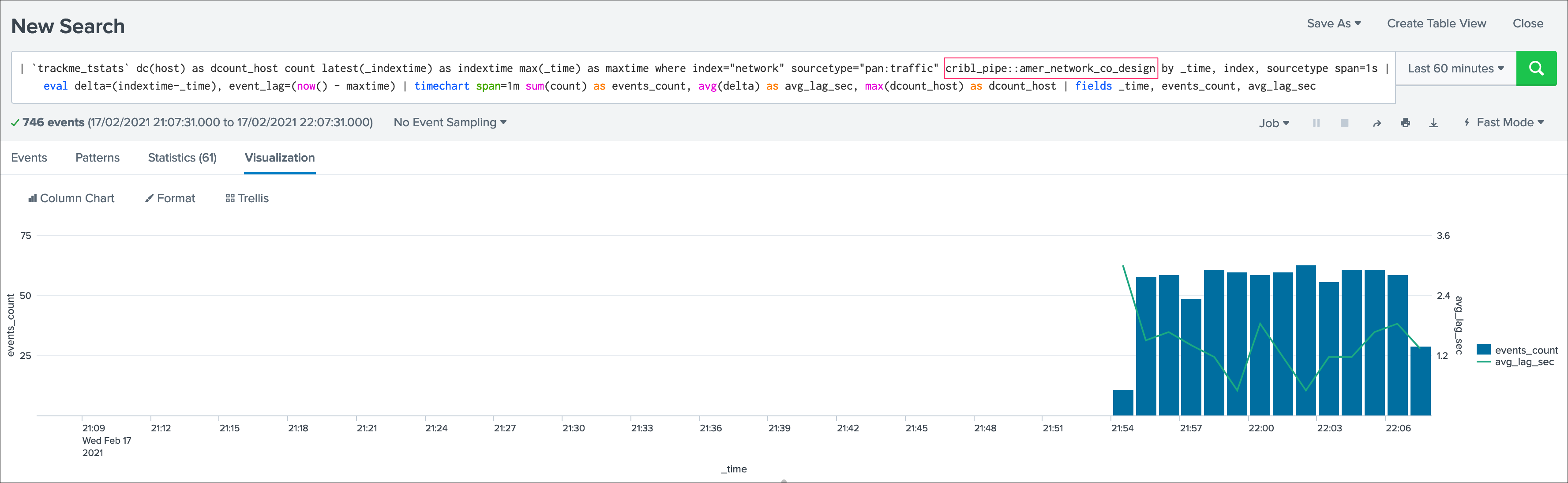
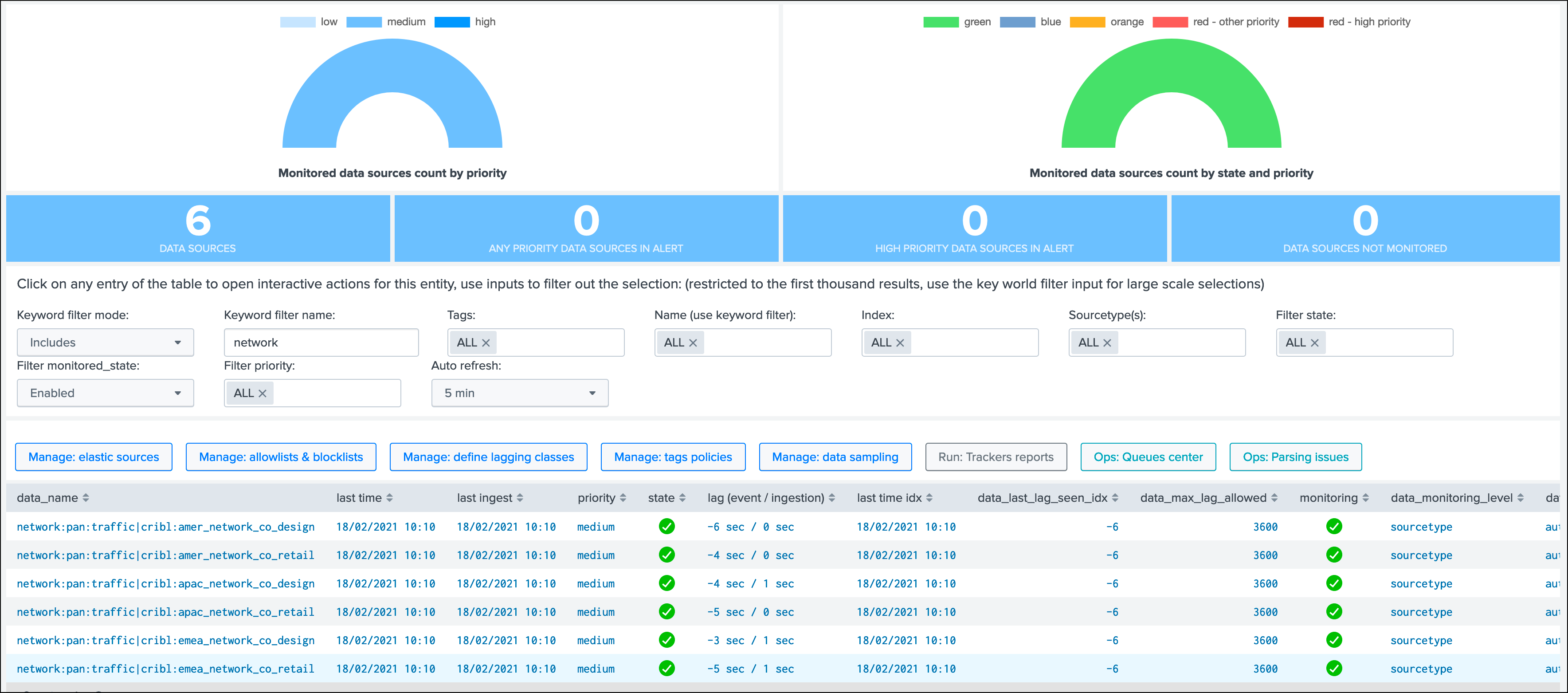
Once we enable the Cribl mode, we see a very different picture, TrackMe automatically creates data sources broken by index, sourcetype and cribl_pipe:
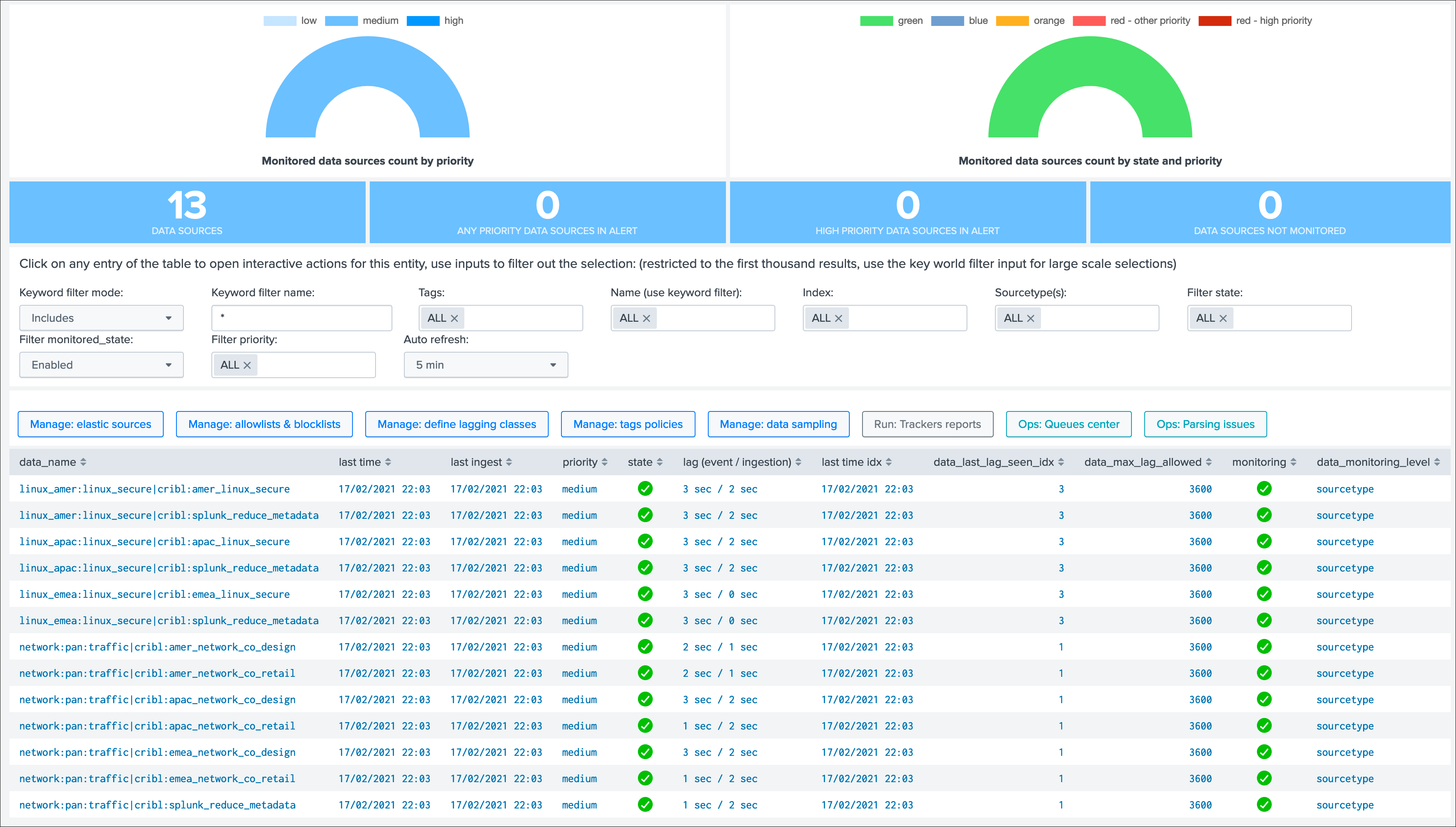
Data sources are created as index + ":" + sourcetype + ":" + cribl_pipe, this represents the data flow from Cribl LogStream to Splunk.
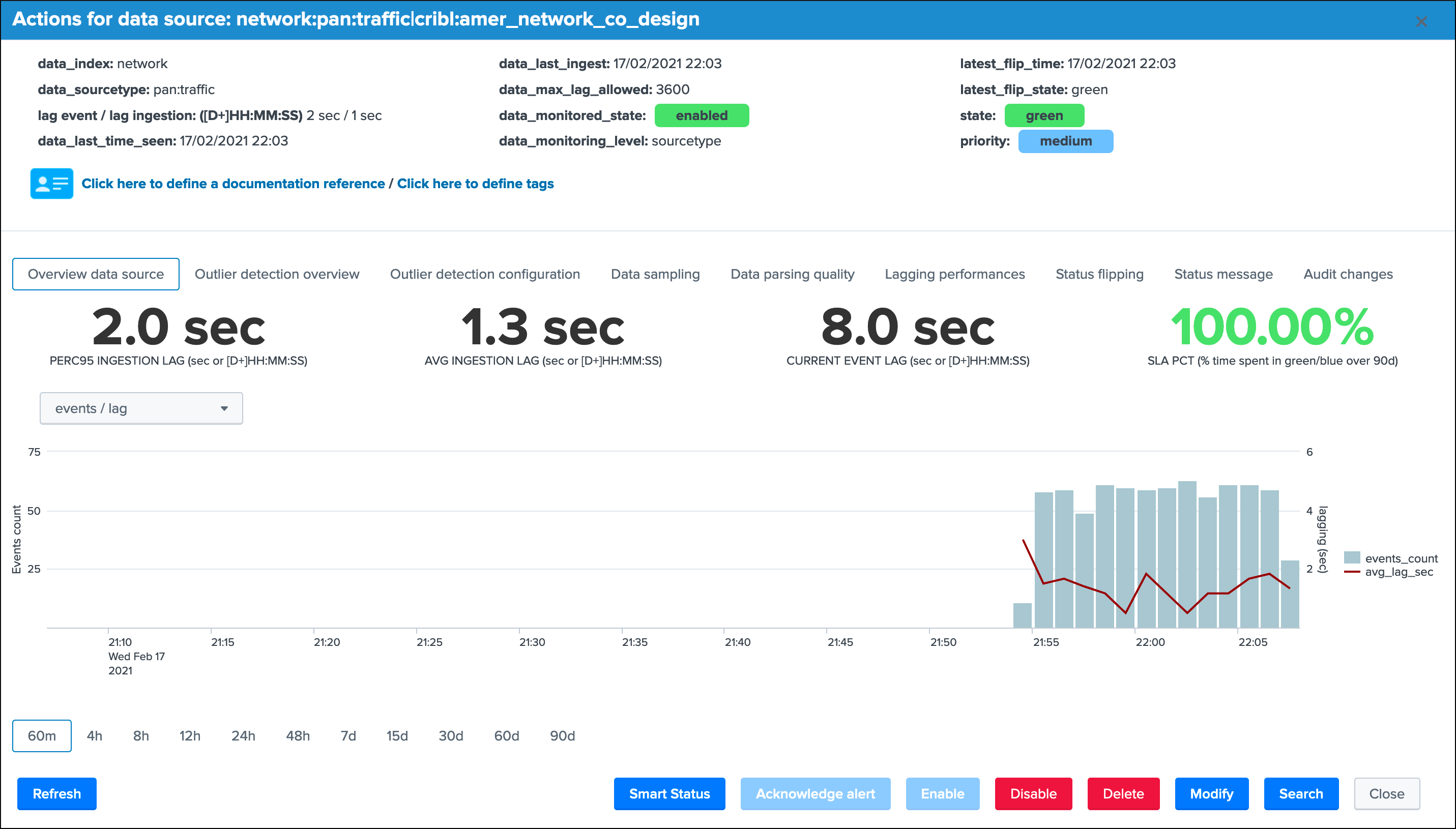
Every search actioned by trackMe now automatically recycles the cribl_pipe information naturally, such as latency tracking, data sampling, open in search buttons, etc:
Cribl LogStream pre-processing pipelines and cribl_pipe field¶
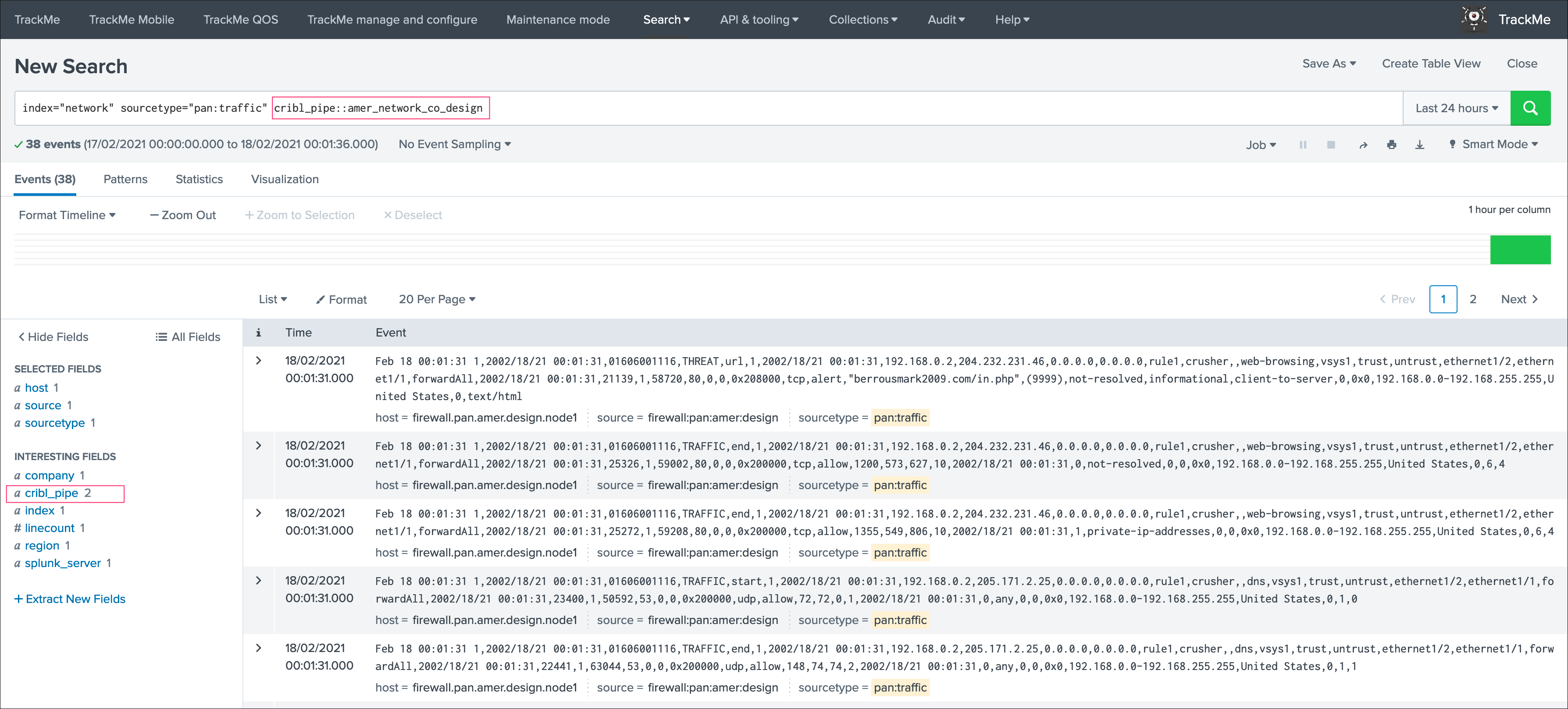
If you have a proprocessing pipelines in your LogStream workflow, the cribl_pipe field becomes a multi-value indexed field that contains both the processing pipeline and pre-processing pipeline:
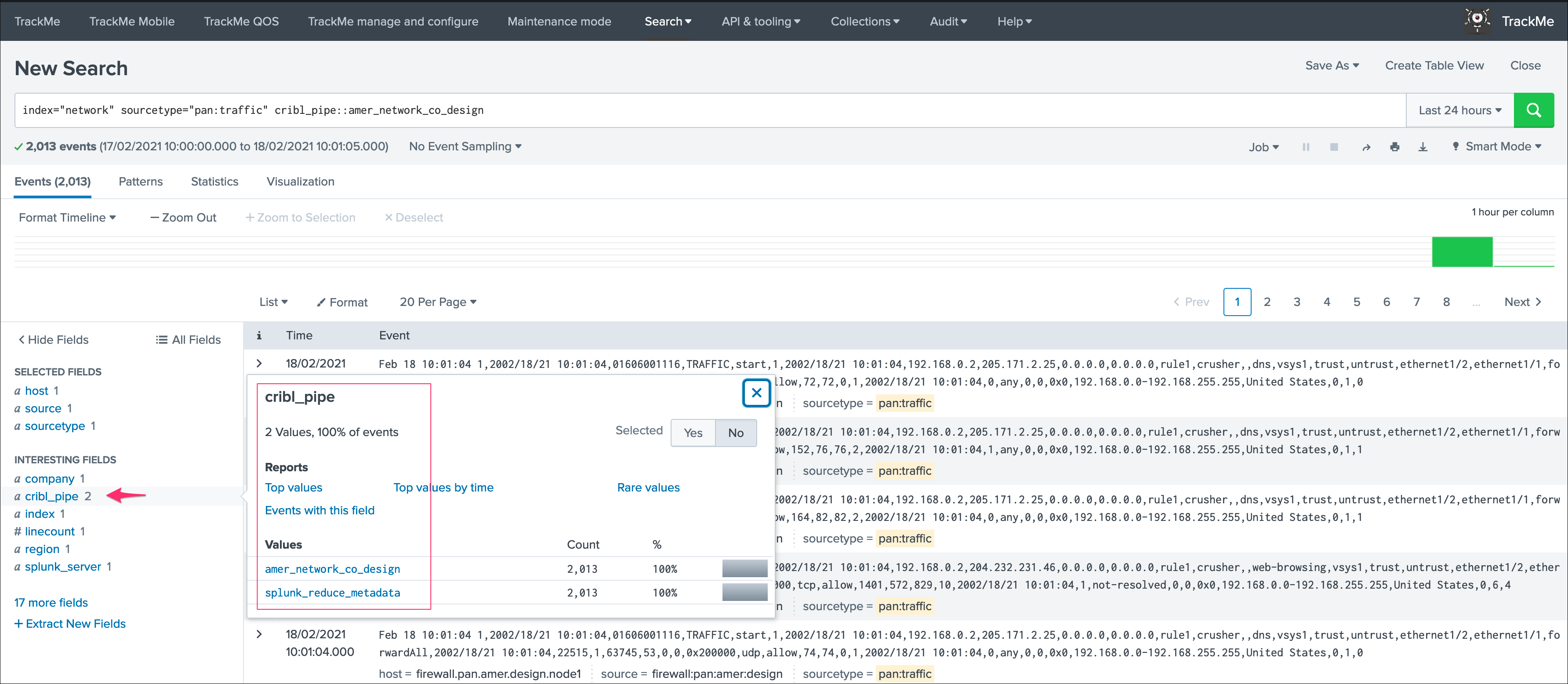
In the TrackMe context, this means that for the same data source, we get at least two entities, one per pipeline and one for the pre-processing pipeline:

From the TrackMe point of view, the pre-processing pipeline view has no value and all that we care about is the data flow itself, to get rid of these entities automatically, we can add a data_name blocklist based in a very simple regular expression:
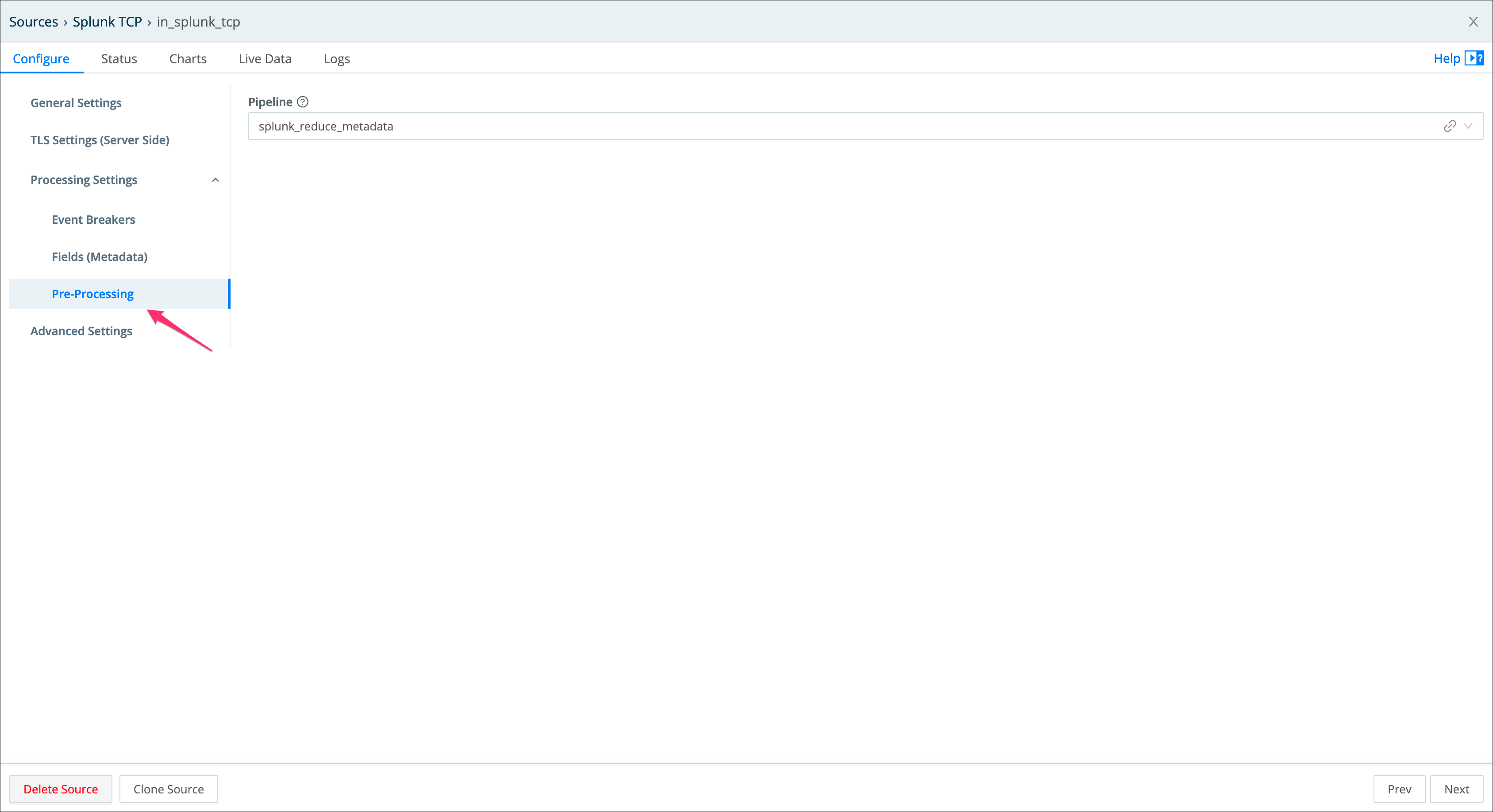
- from the main TrackMe screen, go to “Manage: allowlists & blocklists”
- add a new data_name blocklist according to the name of your pre-processing pipeline, in our case we will use
.*cribl:splunk_reduce_metadata - once it has been added, existing entities are not taken into account anymore, and if new data sources are discovered, these will exclude the pre-processing pipeline automatically

Congratulations!
You have a now a comprehensive integration between the wonderful and amazing Cribl LogStream and TrackMe allowing you to track your Splunk data the easy way!
Handling both Cribl mode and regular mode¶
In some deployments, you may have both Cribl Logstream feeding Splunk, and regular other types of data coming from Universal or Heavy Forwarders.
When TrackMe is configured in the Cribl mode, only data coming from Cribl Logstream will be taken into account, which happens because we expect a cribl_pipe indexed field for every data source to be discovered and maintained.
However, with some minor manual steps, you can easily work in hybrid mode and have data sources handled automatically for both Cribl Logstream originating data, and regular data indexed directly.
This process is currently manual, which might be improved in a future release of TrackMe.
Clone Data sources trackers¶
First, clone the abstract report named TrackMe - Data sources abstract root tracker, example: TrackMe - Data sources abstract root tracker - Not Cribl
This report is used by both the short term and long term trackers to reduce the amount of duplicated SPL lines of codes, you can achieve the clone via Splunk Web (Settings, Searches, reports and alerts), or manually via configuration files if you prefer.
Next, clone the scheduled report named TrackMe - Data sources availability short term tracker, example: TrackMe - Data sources availability short term tracker - Not Cribl
Finally, clone the scheduled report named TrackMe - Data sources availability long term tracker, example: TrackMe - Data sources availability short term tracker - Not Cribl
Update Data sources abstract report¶
Edit the newly created abstract report TrackMe - Data sources abstract root tracker - Not Cribl:
1 - Update the split by condition
Locate in the first line:
by `trackme_data_source_tstats_root_splitby`
And replace with:
by `trackme_data_source_tstats_root_splitby_regular`
2 - Update the where statement
Still in the first line, locate:
where index=* sourcetype=*
And replace with:
where index=* sourcetype=* cribl_pipe!=*
Note: this will ensure these trackers only care about data not originating from Cribl Logstream.
3 - Update the intermediate calculation
locate in the report the line:
| `trackme_default_data_source_mode`
And replace with:
| `trackme_data_source_split_mode`
Update Data sources short and long term trackers¶
For both the short term and long term trackers newly created, edit the report and:
Locate the first line:
| savedsearch "TrackMe - Data sources abstract root tracker"
And replace with:
| savedsearch "TrackMe - Data sources abstract root tracker - Not Cribl"
And that’s it, after the first executions of the newly created tracker reports, any data source that is not coming from Cribl Logstream will be discovered and maintained as usual.
You can immediately run the short term tracker to get regular data sources added to TrackMe.
Note that the “run trackers” buttons in the TrackMe UI will only handle the main default trackers, which is a minor loss of features as you do not normally need to actively execute the trackers.